日体大記録会5000m全記録をデータ化!平均タイム、タイム分布は?
日体大長距離記録会といえば、学生をはじめ多数のランナーが自己ベストを狙って出場する有名な記録会です。毎年数回行われているため、データの収集にはもってこいです。本記事では、日体大長距離記録会の中でも最も出場人数の多い5000mの記録をデータ化してまとめてみました。
平均タイム・タイム分布の記事リンク
年齢別
| 中学 | |
|---|---|
| 高校 | |
| 一般 |
大会別
| MKディスタンス | |
|---|---|
| 日体大記録会 |
データ収集結果
今回は2018年12月と2019年11月、12月のデータを収集しました。2020年は新型コロナの影響で出場が制限されてたいため収集していません。
平均タイム
出走数と平均タイムは以下の通りでした。
| 年月 | 出走数 | 平均 |
|---|---|---|
| 2018/12 | 1946 | 15'34"58 |
| 2019/11 | 1007 | 15'40"58 |
| 2019/12 | 1830 | 15'29"61 |
平均タイムはいずれも15分30秒前後でした。部活生が多数出場しているためレベルは高いです。
箱根駅伝に備えて12月は主力の学生が出場しない傾向あるため、11月の方が平均タイムが速いと思っていたのですが逆でした。この理由をグラフ化してみて探ってみます。
タイム分布
収集したデータを、ヒストグラムにしたものがこちらです。横軸は、ひとつの階級で10秒ごとに区分けしています。縦軸は相対度数(人数の割合)です。
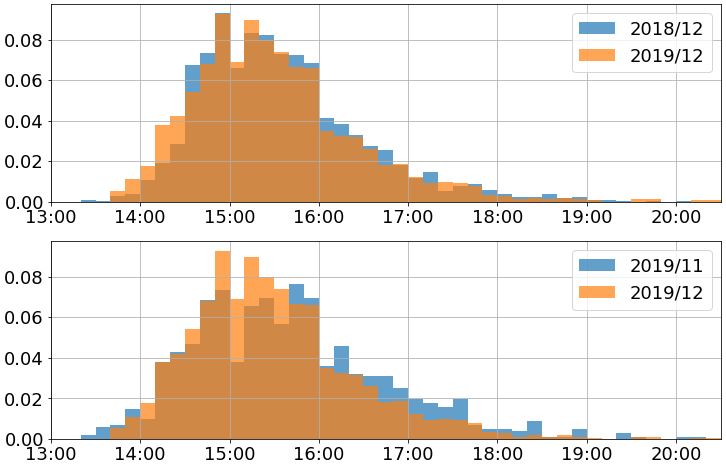
まず3大会全て、15'00" ~ 15'10"の階級が凹んでいることがわかります。これは、15分切りを狙う組が何組かあり、組全体のペースが3'00"/km前後で推移していたためであると思われます。この特徴が3大会全てのヒストグラムに表れていることを考えると、走る組のペースによってゴールタイムがある程度決まってしまうことが裏付けられます。見方を変えれば、目標のペースと合った適切な組で走れれば、自分の力を最大限まで出し切れると考えることもできます。
次に上のグラフですが、これは2018年と2019年の比較をしています。全体的に同じような形をしていますが、2019年の方が若干左にシフトしているようにみえます。コンディションが良かったのか厚底シューズの影響なのか分かりませんが、出場者全体のレベルが高くなったと考えられます(実際平均タイムは2019年の方が5秒速いです)。
最後に下のグラフですが、これは11月と12月の比較をしています。グラフの全体の形を比較すると、11月の方が裾の広い形であることがわかります。つまり、出場選手全体のレベルが11月の方が広いといえます。特に、16'00" ~ 17'30"あたりの割合が大きくなっていることがわかります。13分台を出した選手の割合は11月の方が大きいですが、選手全体のレベルが広い影響で平均タイムは11月の方が遅くなったと考えられます。
偏差値
最後に、一番出走数の多かった2018年12月のデータから、タイムを偏差値化してみました(正規分布と仮定しているため多少誤差はあります)。
| タイム | 偏差値 | 上位 |
|---|---|---|
| 13'18"43 | 75 | 0.6% | 13'45"66 | 70 | 2.2% | 14'00"00 | 67.4 | 4.1% |
| 14'12"89 | 65 | 6.6% | 14'30"00 | 61.2 | 13.1% | 14'40"12 | 60 | 15.9% | 15'00"00 | 56.3 | 26.4% |
| 15'34"58 | 50 | 50.0% | 16'01"81 | 45 | 69.2% | 16'29"04 | 40 | 84.2% |
日体大記録会基準なのでレベルが高いです。模試でいうなら駿台偏差値みたいな感じです。自分で偏差値を計算してみたい場合は、
50 + 10 × (934.58 - タイム(s)) / 54.46
で計算できます。
【参考】データの収集方法
数千人ものデータを1人ずつ集めていくのは不可能に近いので、PythonでWebスクレイピング(ソフトウェア技術を用いたデータ収集)を行いました。以下に2018年12月のデータ収集を例にソースコードの紹介と簡単な解説をします。
まず、5000mの記録がHTMLのどの場所にあるかを開発者ツールを用いて確認します。開発者ツールはF12を押すことで表示されます。
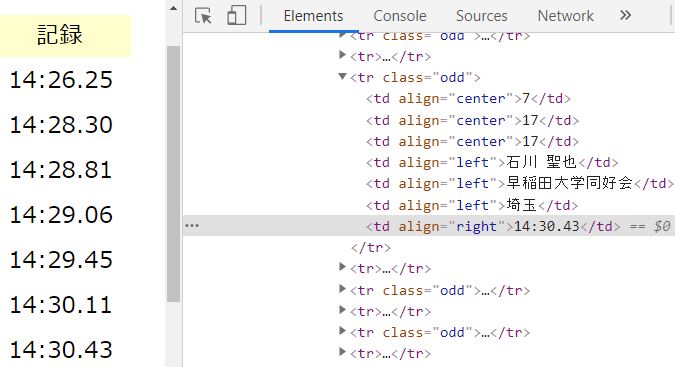
5000mの記録は、tdタグのalign属性がrightの場所にあることがわかりました。そこで、以下のようなコードを書いて、まずは生データを収集してみます。
import bs4, requests, time groups = 43 results = [] for group in range(1, groups+1): res = requests.get(f'http://www.nittai-ld.com/result/pc/C201807/K54-0{group:02}-1-{group:02}.html') res.raise_for_status() nittai = bs4.BeautifulSoup(res.text) runners = nittai.select('td[align="right"]') for i in range(len(runners)): result = runners[i].getText() if len(result) == 8: results.append(result) time.sleep(2)
1行目目で必要なライブラリをインストールしています。今回は、BeautifulSoap(bs4)というWebスクレイピング用のライブラリを使用しました。
6行目以降では、for文で1組ごとに繰り返し処理を行います。1組ごとのHTMLにアクセスし、5000mのタイムをすべて取得します。
13行目のif文では、取得したデータが「14'30"43」のように、8文字のときのみリストに追加します。これは欠場や途中棄権で生じる空欄のデータを取得しないようにするためです。
最終行では、time.sleep関数を用いて、1組のデータ収集が完了後、サイトに負荷をかけ過ぎないように処理を2秒間中断させています。

取得したデータの最初の5件を表示してみました。いい感じに取得できてそうです。取得したデータの数は全部で1946件でした。
取得した生データのままでは文字列として認識されてしまうため、このままではグラフ化することができません。そのため、取得したデータを秒単位の数値に換算します。
time_data = [] for result in results: minute = float(result[0:2])*60 sec = float(result[3:5]) com = float(result[6:8])/100 time_data.append(minute + sec + com)
上のコードを実行したことで、先ほどの文字列のデータが秒単位の数値になりました。

これにより、データをグラフで表すことができるようになります。グラフ化は、matplotlibというライブラリを用いてヒストグラムにして可視化します。
import matplotlib.pyplot as plt import numpy as np fig = plt.figure(figsize=(10,6)) xlim = (780, 1230) xticks = ([780,840,900,960,1020,1080,1140,1200]) xticklabels = (["13:00","14:00","15:00","16:00","17:00","18:00","19:00","20:00"]) ax1 = fig.add_subplot(111, xlim=xlim, xticks=xticks, xticklabels=xticklabels) bins = np.linspace(780, 1240, 47) weights = np.ones_like(time_data) / len(time_data) ax1.hist(time_data, bins, weights=weights, label='2018/12') ax1.grid(True) ax1.legend() plt.show
横軸は見やすくするためにタイム表記に直しています。また、縦軸は絶対度数(データ数)ではなく、比較ができるように相対度数(データ数の割合)に直しています。