MKディスタンス5000m全結果を収集!平均タイムとタイム分布は?
本記事では、多くの市民ランナーが出場するMKディスタンス5000mの全結果を収集し、平均タイムとタイム分布をまとめてみることにしました。
平均タイム・タイム分布の記事リンク
年齢別
| 中学 | |
|---|---|
| 高校 | |
| 一般 |
大会別
| MKディスタンス | |
|---|---|
| 日体大記録会 |
データ収集結果
2020年10,11,12月(非公認の部)の全記録1005人分の結果を収集しました。非公認ということもあり、データには男女どちらのデータも含まれています。
公認の部を収集しなかったのは、タイム制限が設けられている場合があってタイムに偏りが出てしまうためです。
平均タイム・各タイムの割合
平均タイムは17分56秒6でした。日体大記録会の平均タイムは15分30秒前後だったので大きく異なります。
とはいっても、5000mで18分を切れればフルマラソンでサブ3を達成できるくらいの走力はあるはずなのでレベルはそこそこ高いです。
トラックのレースということだけあって、定期的にトラックでポイント練習をしているランナーが多く出場しているのだと思います。
参考までに、各タイムの割合を以下の表に示します。
| タイム | 上位 |
|---|---|
| 15'00" | 2.8% |
| 16'00" | 13.7% |
| 17'00" | 34.5% |
| 18'00" | 54.5% |
| 19'00" | 73.2% |
| 20'00" | 86.2% |
タイム分布
タイム分布はこのようになっていました。横軸は10秒ごとに区分けしています。縦軸は相対度数(データ数の割合)です。
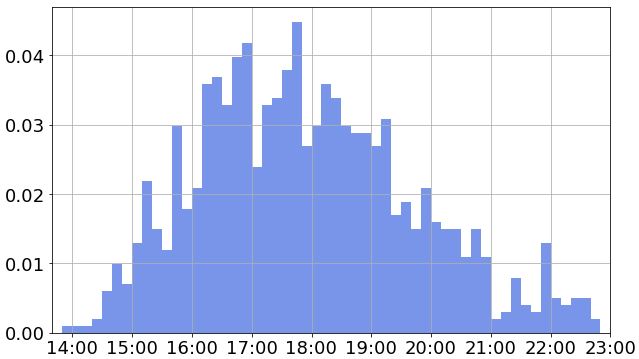
一見きれいな山のような分布にみえますが、何箇所か局所的にピークが立っていることがわかります。これは確実にペースメーカーがいる影響だと思います。
MKディスタンスでは各組にペースメーカーが3人程いるため、ペースメーカーについていくことで集団ができます。そのため、ペースメーカーの目標タイムに近いタイムのところでピークが立っているのだと思われます。
次に日体大記録会(2018/12)との結果と比較してみます。
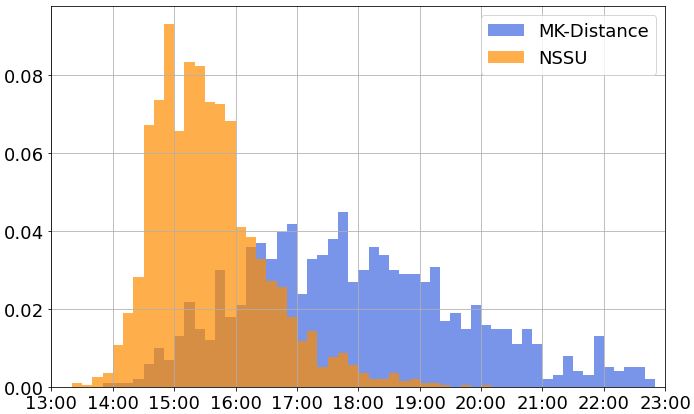
出場しているランナーの層が大きく異なることが分かります。日体大記録会は部活生が多く出場しているためレベルが高いです。
他の特徴として、縦軸(相対度数)の最大値も大きく異なることが分かります。MKディスタンスの方が最大値が半分くらいになっていて、その分グラフの山が横に広がっています。
つまり、出場しているランナーの層が日体大記録会よりも広く、初心者でも出場しやすい大会だといえます(さらに非公認の部なら陸協登録も不要です)。
【参考】データの収集方法
全記録を手動でデータを集めると相当時間がかかってしまうので、Pythonを用いて自動的にデータ収集を行いました。
日体大記録会とは異なり、MKディスタンスはリザルトがPDFで公開されているので(日体大記録会も2020年からPDFに変わっています)、MKディスタンスHPよりダウンロードしたリザルト(PDF)からPyPDF2というライブラリを使用して記録の部分のみを抽出することにしました。
そこで、まずは1ページ目のデータを表示しようと思ったのですが、、、
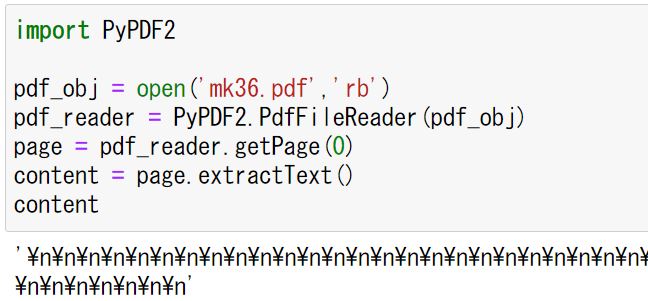
なぜか改行のエスケープシーケンスが大量に出てきてしまいました。PyPDF2は文字の抽出が上手くいかないことがあるようで、今回は抽出失敗ということになります(詳しい方がいたら教えてくださると嬉しいです)。代替手段として、PDFファイルをWordで開き、Wordから記録を抽出することにしました。
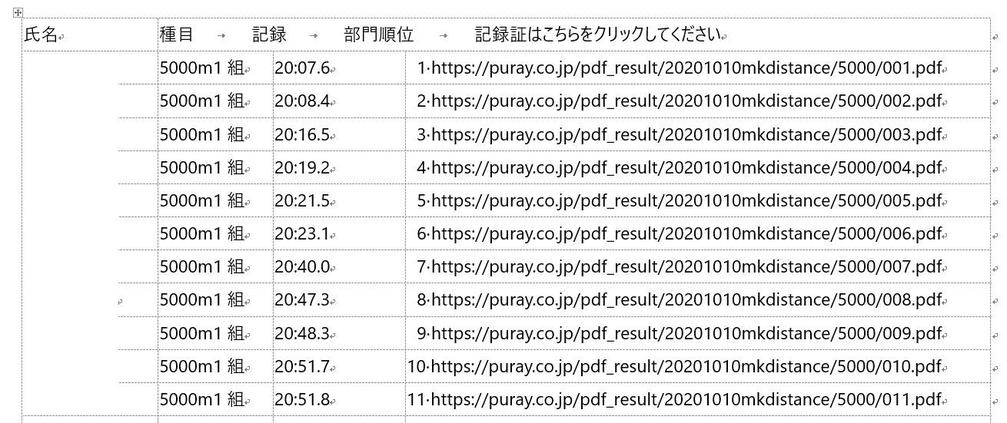
リザルトのPDFをWordで開くと、このように表になって表示されました(氏名の部分は白塗りしています)。記録を収集するには表の3列目のみを抽出すれば良さそうです。データの抽出はPython-Docxというライブラリを用いて行いました。
import docx doc = docx.Document('mk36.docx') results = [] #データの収集開始 for i in range(len(doc.tables)): tbl = doc.tables[i] #1行ずつ繰り返し処理 for row in tbl.rows: #記録を追加(DNSなどは抽出しない) if len(row.cells[2].text) == 7: results.append(row.cells[2].text)
データの抽出結果がこちらです。少し手間がかかってしまいましたが全記録の収集ができました。
抽出したデータは文字列として認識されているため、秒単位の数値に変換しヒストグラムにして可視化します。コードは日体大記録会のデータ収集のときとほとんど同じです。